public class SimpleChunkProvider<I> implements ChunkProvider<I> {
protected final Log logger = LogFactory.getLog(getClass());
protected final ItemReader<? extends I> itemReader;
private final MulticasterBatchListener<I, ?> listener = new MulticasterBatchListener<>();
private final RepeatOperations repeatOperations;
public SimpleChunkProvider(ItemReader<? extends I> itemReader, RepeatOperations repeatOperations) {
this.itemReader = itemReader;
this.repeatOperations = repeatOperations;
}
...
@Override
public Chunk<I> provide(final StepContribution contribution) throws Exception {
final Chunk<I> inputs = new Chunk<>();
repeatOperations.iterate(new RepeatCallback() { //반복자
@Override
public RepeatStatus doInIteration(final RepeatContext context) throws Exception {
I item = null;
Timer.Sample sample = Timer.start(Metrics.globalRegistry);
String status = BatchMetrics.STATUS_SUCCESS;
try {
item = read(contribution, inputs); //Reader.read()
}
catch (SkipOverflowException e) {
// read() tells us about an excess of skips by throwing an
// exception
status = BatchMetrics.STATUS_FAILURE;
return RepeatStatus.FINISHED;
}
finally {
stopTimer(sample, contribution.getStepExecution(), status);
}
if (item == null) {
inputs.setEnd();
return RepeatStatus.FINISHED;
}
inputs.add(item); //반복자 끝날 때까지 inputs에 추가
contribution.incrementReadCount();
return RepeatStatus.CONTINUABLE;
}
});
return inputs;
}
}
public class SimpleChunkProcessor<I, O> implements ChunkProcessor<I>, InitializingBean {
private ItemProcessor<? super I, ? extends O> itemProcessor;
private ItemWriter<? super O> itemWriter;
private final MulticasterBatchListener<I, O> listener = new MulticasterBatchListener<>();
...
@Override
public final void process(StepContribution contribution, Chunk<I> inputs) throws Exception {
// Allow temporary state to be stored in the user data field
initializeUserData(inputs);
// If there is no input we don't have to do anything more
if (isComplete(inputs)) {
return;
}
// Make the transformation, calling remove() on the inputs iterator if
// any items are filtered. Might throw exception and cause rollback.
Chunk<O> outputs = transform(contribution, inputs);
// Adjust the filter count based on available data
contribution.incrementFilterCount(getFilterCount(inputs, outputs));
// Adjust the outputs if necessary for housekeeping purposes, and then
// write them out...
write(contribution, inputs, getAdjustedOutputs(inputs, outputs));
}
}
protected Chunk<O> transform(StepContribution contribution, Chunk<I> inputs) throws Exception {
Chunk<O> outputs = new Chunk<>();
for (Chunk<I>.ChunkIterator iterator = inputs.iterator(); iterator.hasNext();) {
final I item = iterator.next();
O output;
Timer.Sample sample = BatchMetrics.createTimerSample();
String status = BatchMetrics.STATUS_SUCCESS;
try {
output = doProcess(item);
}
catch (Exception e) {
/*
* For a simple chunk processor (no fault tolerance) we are done
* here, so prevent any more processing of these inputs.
*/
inputs.clear();
status = BatchMetrics.STATUS_FAILURE;
throw e;
}
finally {
stopTimer(sample, contribution.getStepExecution(), "item.process", status, "Item processing");
}
if (output != null) {
outputs.add(output);
}
else {
iterator.remove();
}
}
return outputs;
}
protected final void doWrite(List<O> items) throws Exception {
if (itemWriter == null) {
return;
}
try {
listener.beforeWrite(items);
writeItems(items);
doAfterWrite(items);
}
catch (Exception e) {
doOnWriteError(e, items);
throw e;
}
}
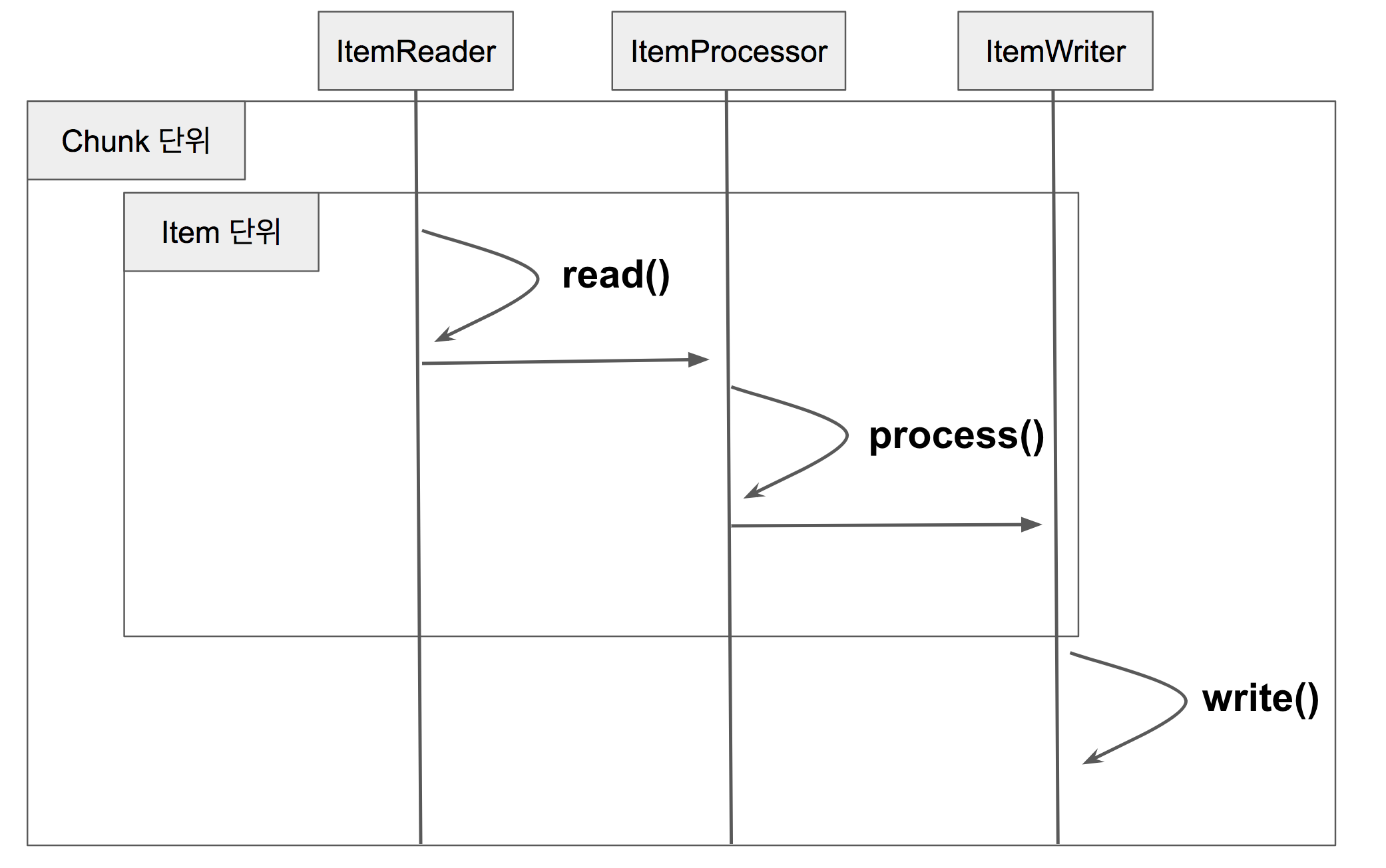
Comments