spring batch(1) 기본개념
Spring Batch 기능
- 스프링 배치는 당연히 Spring core 모듈에 대한 의존관계를 가지고 있으며 그에 따라 POJO 기반의 개발, 유연한 설정법, AOP 적용 등 기존 스프링의 장점을 그대로 이어받았다.
1. 각종 읽기와 쓰기 기능의 구성요소를 같은 인터페이스들로 추상화 시키고 있고 그에 맞는 기본 구현 클래스를 제공
- DB, 플랫파일, XML 파일, JMS(Java Message Service) 등의 여러가지 출처와 형태로 연결되는 데이터들을 ItemReader와 ItemWriter라는 인터페이스를 통해 동일한 방식으로 접근할 수 있다.
- 인터페이스는 각각의 요소들의 역할 구분을 분명히 하고, 데이터 형태의 변화에 대응하는 유연성을 높일 수 있다.
- 부분적인 모듈의 테스트도 쉽게 할 수 있다.
2. 대용량 조회 처리를 위해 커서기반이나 Driving query기반의 조회방식 지원
- 전자가 JdbcCursorItemReader나 HibernateCursorItemReader 클래스로 제공되고, 후자가 DrivingQueryItemReader, IbatisDrivingQueryItemReader 클래스를 통해 지원된다.
3. Stream방식의 파일 처리를 더욱 편리하게 할 수 있는 API를 제공
- 열고 닫는 것이 필요한 자원에는 공통적으로 ItemStream이라는 인터페이스를 통해 이를 지원한다.
- StAX(Streaming API for XML) 기반의 API로 대용량 XML파일 처리를 쉽게한다.
- Spring Web Service 프레임워크의 일부인 Spring OXM(Object/XML Mapping framework)과 연결해서 특정 라이브러리에 종속적이지 않은 XML 파일 처리도 가능하다.
4. 배치에 적합한 트랜잭션 처리를 위해 주기적인 commit 방식 지원
- SimpleStepFactoryBean 클래스를 통해 설정할 수 있는 commitInterval이라는 속성이 한번의 트랜잭션에서 처리될 수
- 데이터 특성이나 업무규칙에 따라 적절한 값을 트랜잭션 단위로 묶이는 건수를 Java 코드를 수정하지 않고도 설정으로 지정할 수 있다.
5. 배치작업의 재시도, 재시작, 건너뛰기 등의 정책을 설정으로 적용함
- 스프링 배치에서는 네트워크 이상 같은 일시적인 장애로 인한 처리 실패를 대비해서 배치작업을 재시도하는 횟수를 지정할 수 있다.
- 재시작 시에는 이미 성공한 단계에 대해서는 건너뛸 수 있는 기능이 있고, ExecutionContext라는 저장 공간을 통해 이전 처리 때 생성한 정보를 활용할 수 있다.
6. 유연한 Exception 처리
- Skip 해야 할 Exception, 또는 그 Skip 할 수 있는 횟수 등을 정의해서 업무 로직의 특성에 맞는 Exception 처리를 복잡한 try catch문 없이 설정만으로 할 수 있다.
7. 각종 이벤트 처리
- Batch Job과 그것을 구성하는 단계 또는 트랜잭션의 단위 별로 그 시작과 끝, 에러 발생 시점에 호출되는 Listener 인터페이스가 정의
- Listener들을 구현해서 코딩하고 설정으로 연결하면 공통적인 작업들을 Batch 처리 코드와 섞이지 않게 넣어서 실행시킬 수 있다.
8. Commit 개수, Rollback 개수, 재시도 횟수 등 배치실행 통계정보를 제공
- 개발자가 작성하는 코드에서 별도로 이를 위한 변수를 할당하고 로깅하는 코드를 집어 넣어줘야 필요가 없어졌다.
9. 다양한 실행방법을 선택
- Spring의 Quartz 지원 클래스를 이용해서 스케줄링 기능을 Spring의 설정방식으로 지정할 수 있다.
- 수동으로 command line이나 JMX(Java Management Extensions) 콘솔 등을 통한 실행도 가능하다. 실행방식도 동기, 비동기-병렬 실행이 가능
10. 추가 코딩없이 설정만으로 기존 모듈 활용
- 기존 모듈 중 배치에서 하는 것과 동일한 작업을 하는 코드가 있다면 따로 스프링배치의 인터페이스로 감싸서 코딩할 필요없이 applicationContext에서 설정만으로 연결이 가능하다.
- 기존모듈을 활용하면서도 스프링배치가 제공하는 이벤트처리, 실행정보 제공 등의 장점을 누릴 수 있다.
11. iBatis나 Hibernate를 사용해서 DB접근모듈을 개발
12. Validation 기능을 SpringValidator와 apache commons validator를 사용해서 구현
스프링 배치 구조
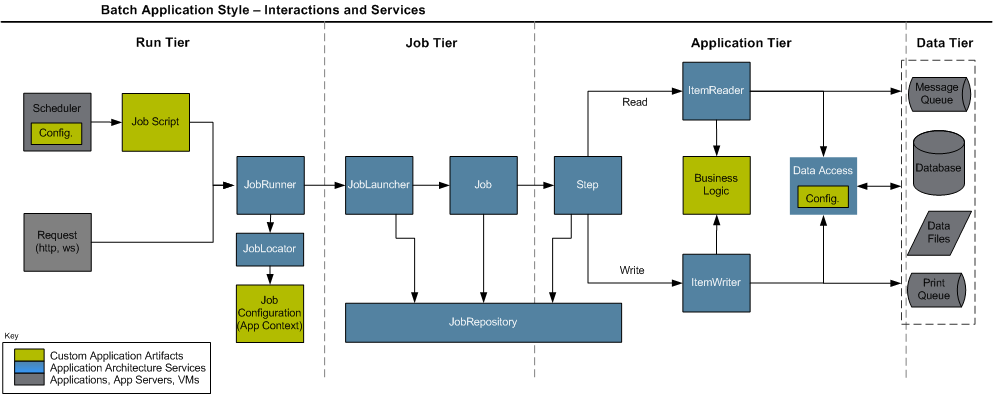
JobRepository
- 배치 실행중 발생하는 정보를 저장하는 저장소
- Job의 시작 및 종료시간, 실행횟수, 실행결과 등 배치작업과 관련된 메타데이터가 저장됨
- DataBase방식, Memory방식
JobLauncher
- 배치 작업을 실행시키는 역할 수행
- Job과 JobParameter를 이용하여 요청된 Batch 작업을 실행 후 JobExecution 반환
- taskExecutor설정에서 SyncTaskExecutor(default), SimpleAsyncTaskExecutor (동기, 비동기)로 나눠짐
Job Runner
- 외부 실행 모듈과 JobLauncher를 연결해주는 모듈
- 스프링 배치는 Scheduling 기능을 제공하지 않아 Quartz나 Cron 사용을 권고함
-
Command Line방식
java CommandLineJobRunner [설정파일명] [job이름] [Job Parameter A=B형태] - Web 방식
@RequestMapping(value="/batchRun.do", method=RequestMethod.POST)
public String batchRun(@RequestParam(value="jobName", required=false) String jobName,
@RequestParam(value="async", required=false) String async, Model model){
try{
JobExecution jobExecution = jobLauncher.run(jobRegisty.getJob(jobName), getUniqueJobParameters(jobName));
...
Job
- 스프링 배치를 통해 작성하고 관리할 작업의 최소단위
- 하나의 Job은 하나 혹은 그 이상의 Step으로 구성
Step
- 실질적인 배치 처리 내용을 정의하고 있는 객체
- 하나의 Job에는 최소 1개 이상의 Step이 있어야 함
- 읽기 -> 가공 -> 쓰기 의 묶음. 이 묶음을 Chunk Processing 라고 부름
- JobExecution에 대응되는 StepExecution이 존재함
- Chunk 지향처리 : 데이터를 item 단위로 읽고 처리하고 쓰는 방식(Spring Batch 기본유형)
- Tasklet 처리 : 단일 테스크나 커스텀한 코드를 수행하기 위한 처리 방법(Tasklet 인터페이스 직접 구현)
Chunk
- 한 번의 오퍼레이션을 통해 다룰 데이터의 집합. 각 Step은 설정에 정의된 chunk 단위에 따라 데이터를 읽어 들이고, 가공한 후 기록
- Step의 설정에서 chunk의 크기를 결정
- 크기의 단위는 데이터베이스의 한 row일 수도 있고, CSV파일의 한 줄일 수도 있다.
- 데이터베이스 작업을 수반하는 Step이라면 이 chunk를 처리하는 동안 스프링배치는 컴포넌트 간에 계속하여 TX를 전파하고 마지막 처리가 끝나는 시점에 TX를 커밋하거나 롤백
- Spring Data JPA를 사용해 Step을 구성하는 경우, chunk의 이런 속성은 영속성 컨텍스트의 생성/소멸 주기와도 관련 있으므로 유념해야한다.
Chunk 지향 처리
- Spring Batch에서 일반적으로 사용하는 Step 유형
- 데이터를 일정크기의 Chunk 단위로 데이터를 처리하는 방법
- 읽기(Read) -> 처리(Processor) -> 쓰기(Writer)의 단계를 거치는 매커니즘
- 처리할 데이터가 없을때까지 반복해서 실행
- 지정된 Chunk 단위(commit-interval)만큼 쌓일 때까지 ItemReader, ItemProcessor 과정을 반복수행하고 Chunk 단위만큼 쌓이면 ItemWriter에 일괄 전달하여 저장
commit-interval="100"지정 후 배치 실행해서 250번째 데이터를 읽고 처리하는 도중 오류 발생시 1~200번 데이터까지만 저장됨- 재 실행할경우 실패한 부분(201~)부터 이어서 실행됨(chunk 개수를 바꾸고 재실행해도 실패한 부분부터 이어서 실행)
Tasklet 인터페이스 직접 구현
- 단일 태스크 또는 커스텀한 코드를 수행하기 위한 처리 방법
- 단순 파일의 복사 및 이동, DB의 프로시저 호출등의 단순한 처리를 메소드 하나로 구현하고 싶을 경우 사용
ItemReader<Input>
- 배치 작업의 대상이 될 데이터를 읽어 들이는 컴포넌트
- chunk를 통해 정의한 입력 데이터의 타입과 같은 타입의 데이터를 읽어 들이게 구현
ItemProcessor<Input, Output>
- 데이터를 비즈니스 로직에 따라 가공하고, 변경된 데이터를 리턴하는 컴포넌트
ItemWriter<Output>
- 추출 및 가공이 완료된 데이터를 정해진 곳에 저장/색인
JobInstance
- 작업의 독립된 실행단위
- 하나의 JobInstance는 고유한 JobParameter를 갖고, JobParameter는 JobInstance 객체의 동등성을 평가하는 기준이 됨
- JobInstance에는 기본값으로 UNIQUE 조건이 부여되므로, 원칙적으로 같은 JobParameter를 가진 두개 이상의 JobInstance는 생성될 수 없다.
- JobInstance는 1개, JobExecution은 여러개 생성 될 수 있음
JobParameters
- 하나의 Job에 존재할 수 있는 여러 JobInstance를 구별하기 위한 Parameter 집합
- Job을 식별하거나 Job에서 참조하는 데이터로 사용
- JobParamter를 통해 여러 JobInstance 생성 가능
JobExecution
- 작업의 독립된 실행 단위인 JobInstance에 대한 한 번의 실행 시도
- 각 Job은 재시작 여부를 결정하는 flag인
boolean restartable = false을 갖는다. - 명시적으로 재시작 가능 옵션을 설정하면 하나의 JobInstance는 여러개의 JobExecution을 가진다.
StepExecution
- Job이 갖고 있던 하나의 Step에 대한 한 번의 실행 시도
Comments